Normalizing flows
Table of Contents
Literature
- wu20_stoch_normal_flows: Stochastic Normalizing Flows
- Considering a sequence of flows

- Instead of composing these determinstically, they interleave sampling steps from some transition kernel
- Considering a sequence of flows
- huang20_augmen_normal_flows
Results
- There exists normalizing flows which are "universal" in the sense that they can express any distribution (i.e. "weak" convergence). huang18_neural_autor_flows,papamakarios19_normal_flows_probab_model_infer
"Why the name?!"
I've received this question or a similar one on more than one occation. Normalizing flows is really not a good name for what it is supposed to represent. It is also unclear whether or not it refers to the base distribution together with the transformation, or just the transformation itself, ignoring the base distribution which is transformed.
I've received questions such as
- "Is this related to gradient flows in differential equations and manifolds?" which is a completely valid question because that is indeed what it sounds like it is! I'd say something like "Well, kind of, but also not really. A gradient flow could technically be used in a normalizing flow but it's way too strict of an requirement; you really just need a differentiable bijection with a differentiable inverse. A gradient flow is indeed this (at least locally), but yeah, you can also just have, say, addition by a constant factor."
Today, I'd say a normalizing flow is a piecewise [[file:..mathematicsgeometry.org::def:diffeomorphism][diffeomorphic]] [[file:..mathematicsmeasuretheory.org::def:push-forward-measure][push-forward]], or in simpler terms, it's a differentiable function 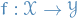 with a differentiable inverse
with a differentiable inverse 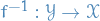 together with a base distribution
together with a base distribution  on
on  with a density
with a density ![$p: \mathcal{X} \to [0, 1]$](../../assets/latex/normalizing_flows_2b87150938eb7795f53ab3a3d19d8665b84a4ba6.png) .
.
So, why isn't it just called a this? It seems like the term normalizing flows was popularized in 2014 by rezende15_variat_infer_with_normal_flows. This paper refers to the "method of normalizing flows" from tabak2010density in which we can probably find the first use of the term. In this work they do the following
Define

where
 is a known density and
is a known density and  denotes the Jacobian of the map
denotes the Jacobian of the map 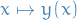 .
.
Define the mapping
 as an "infinite composition of infinitesimal transformations", i.e. a (gradient) flow
as an "infinite composition of infinitesimal transformations", i.e. a (gradient) flow  s.t.
s.t.
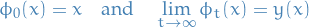
Define

then

Given a set of samples
 , we can measure the quality of the estimated density
, we can measure the quality of the estimated density  by the log-likelihood, treating it as a functional on
by the log-likelihood, treating it as a functional on  :
:
![\begin{equation*}
L[\phi_t] = \frac{1}{m} \sum_{j=1}^{m} \log \tilde{\rho}_t(x^j)
\end{equation*}](../../assets/latex/normalizing_flows_327ab63fbbd81d7e07838884596792a3e1b5a78b.png)
This suggests constructing the flow
by following the direction of ascent of ![$\mathcal{L}[\phi_t]$](../../assets/latex/normalizing_flows_cdb03783f4510efab0fe045a8cfd1cdf423480bd.png) , i.e. s.t.
, i.e. s.t.
![\begin{equation*}
\dv{}{t} L[\phi_t] \ge 0
\end{equation*}](../../assets/latex/normalizing_flows_c2187c2a57f5f47dc91c7cfe8d809414fee190dd.png)
and such that
 is the (local) minimizer.
is the (local) minimizer.

where
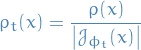
Note that
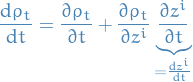
In this work they describe a method of defining a (gradient) flow
Basically, in this work they define a gradient flow using the log-likelihood which transforms from a known density  to the unknown density
to the unknown density  . They also consider the dual of the flow, which transforms from to , which they refer to as "transforming to normality", i.e. a normalizing flow in the sense that it's a flow which transforms a density to normality / a normal distribution. For practical purposes they consider "infinitesimal" small additive changes, which is basically what we today refer to as residual normalizing flows behrmann18_inver_resid_networ. They also point out that the work of "Gaussianization" which was done in 2002 follow a similar idea, though not using flows.
. They also consider the dual of the flow, which transforms from to , which they refer to as "transforming to normality", i.e. a normalizing flow in the sense that it's a flow which transforms a density to normality / a normal distribution. For practical purposes they consider "infinitesimal" small additive changes, which is basically what we today refer to as residual normalizing flows behrmann18_inver_resid_networ. They also point out that the work of "Gaussianization" which was done in 2002 follow a similar idea, though not using flows.