Linear Programming
Table of Contents
Overview
Linear programming is a technique for the optimization of a linear objective function, subject to linear equality and linear inequality constraints.
It's feasible region is a convex polytope.
Linear programs are problems that can be expressed in canonical fomr as:

Notation
 denotes the vector of variables
denotes the vector of variables and
and  are vectors of known coefficients
are vectors of known coefficients is # of constraints
is # of constraints is # of variables
is # of variables![$i \in [m]$](../../assets/latex/linear_programming_6e030bd42161adc7d1c9cd693914d31ec6617bff.png) and
and ![$j \in [n]$](../../assets/latex/linear_programming_be37fe04d5d06f5ca7309611d64a9ce72f85f3ad.png) where
where ![$[n] = \{ 1, 2, \dots, n \}$](../../assets/latex/linear_programming_7ac40486ab20ce81a233ac7437781e207bf02777.png)
 denotes the set of feasible / possible solutions
denotes the set of feasible / possible solutions
From the basics
Consider the following LP problem:
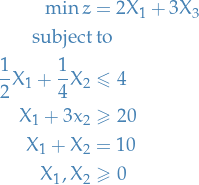
Then observe the following:
We an rewrite the objective:

I.e., minimizing
 corresponds to finding
corresponds to finding  and
and 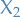 such that the smallest value can take on and still satisfy the equality is as small as possible!
such that the smallest value can take on and still satisfy the equality is as small as possible!
We can rewrite an equality of the form

EXPLAIN THIS PROPERLY
If we do this for all inequalities, we observe that we're left with a simple linear system:
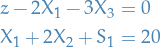
Which we can simply solve using the standard Linear algebra! There are a couple of problems here though;
- Not encoding the minimization of the objective
- Not encoding the fact that the variables are non-negative (positive or zero)
- If
 , i.e. have more variables than constraints, then we have multiple possible solutions
, i.e. have more variables than constraints, then we have multiple possible solutions
Therefore we have to keep track of these two points ourselves;
The Simplex Method is a method which helps us with exactly that by doing the following:
- Gives us certain conditions which have to be true if the solution we're currently considering is hte best solution we can in fact obtain
- How to obtain other solutions given the solution we're currently considering (where we can just check which one is the best one by comparing the values takes on for the different solutions)
To address the first point: "how do we know that the solution under consideration is best ?" we make the following observation
 then
then 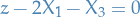 will have the best possible value of if
will have the best possible value of if  , right?
, right?
- Since the coefficients of and are both negative, then any increase in the values of and will lead to decrease in the objective function !
- Since the coefficients of
The Simplex method makes use of this fact by observing that if we can transform the system of linear equations such that the coefficients of 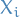 are all
are all
Introduction
We are given an input of the following constraints (inequalities):
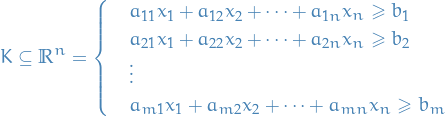
where  for and . And then we have some (linear) objective function we want to optimize wrt.
for and . And then we have some (linear) objective function we want to optimize wrt.  , i.e. such that the above constraints are satisfied.
, i.e. such that the above constraints are satisfied.
Can always change the "direction" of the inequalities by simply multiplying one side by -1.
Also allow equality since

but NOT strict inequalities!
Fourier-Motzkin Elimination
Let's do an example: assume that we're working with a 3-variable 5-constraint LP, namely,
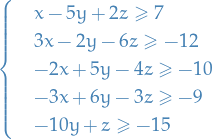
Fourier-Motzkin elmination is then to recursively eliminate one of the variables. Let's do  first:
first:
"Normalize" the constraints wrt.
, i.e. multiply constraints by constants such that coeff. of is in 
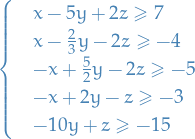
Write inequalities as:

for some
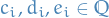 depending on whether has coefficient
depending on whether has coefficient  or
or  (if coeff is 0, we just leave it). Then we get,
(if coeff is 0, we just leave it). Then we get,
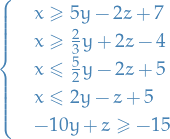
where we for example have done:

For each pair of "different" inequalities, we "combine" them to form:
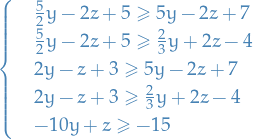
Thus we have eliminated
!
- Repeat step 3 until we only have a single variable left, leaving us with a set of constraints for this last variable. If the constraints remaining cannot be satisfied by the remaining variable, then clearly this is an infeasible problem, i.e.
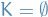 .
.
Fourier-Motzkin Elimination actually solves the LP-problem; however, it does so incredibly inefficiently. As we'll see later, these problems can be solved in polynomial time.
FM elimination start out with  inequalities, and in the worst case we end up with
inequalities, and in the worst case we end up with  new inequalities (due to pairing up all the "different" inequalities).
new inequalities (due to pairing up all the "different" inequalities).
Equational / canonical form
We can constrain every variable  to be
to be  by introducing two variables
by introducing two variables 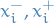 for each variable . Then replace each occurence of by
for each variable . Then replace each occurence of by  and add the constraints
and add the constraints 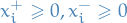 .
.
In doing so we end up with a positive orthant in 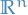 and constraints
and constraints  is a
is a  dimensional subspace of .
dimensional subspace of .
TODO LP and reduction
Solving LP (given feasible)
First we want to find
Suppose  . Then we only need to find
. Then we only need to find  such that
such that
![\begin{equation*}
K \cap \{ x_i = d_i, \forall i \in [n] \} \ne \emptyset
\end{equation*}](../../assets/latex/linear_programming_fb95cf05abb1efe89968c109796dcf8977b9cc08.png)
i.e. some feasible solution 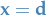 .
.
We also assume that the feasible set is /bounded/1, where ![$x_i \in [B_i^-, B_i^+]$](../../assets/latex/linear_programming_480796f85184580796b392c2dbb21e15ae0a7011.png) . We then use binary search to
. We then use binary search to
Basic feasible solution
In geometric terms, the feasible region defined by all values of such that

is a (possibly unbounded) convex polytope. There is a simple characterization of the extreme points or vertices of this polytope, namely an element 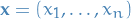 of the feasible region is an extreme point if and only if the subset of column vectors
of the feasible region is an extreme point if and only if the subset of column vectors  corresponding to the non-zero entries of (
corresponding to the non-zero entries of ( ) are linearly independent.
) are linearly independent.
In this context, such a point is know as a basic feasible solution (BFS).
The BFS will always be of the same dimension as the number of constraints. That is,

since the number of constraints determines the number of independent variables in our system. Why? Well, if we have 3 variables and 2 constraints, then that means that one of the variables, say  , can be expressed as a function of one of the other variables, say
, can be expressed as a function of one of the other variables, say  , and so on.
, and so on.
What does this mean? We can obtain some initial BFS by setting enough variables to zero such that we're left with only variables (where we should have only one variable being non-zero in each constraint). In this way we obtain some linearly indep. system from which we can start pivoting.
We call the variables currently in the basis basic variables, and those not in the basis non-basic variables.
TODO Initial BFS
- If all the constraints in the original LP formulation are of the
 type, we can readily obtain an initial BFS for Simplex, consisting of all the slack variables in the corresponding standard form formulation
type, we can readily obtain an initial BFS for Simplex, consisting of all the slack variables in the corresponding standard form formulation - Need to find an initial BFS, since we might not start with a matrix which has perpendicular columns (i.e. the columns are not orthonormal)
Consider the following general linear problem:
which in "standard form" becomes
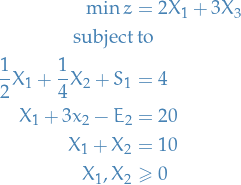
where we've turned the inequalities into equalities by introducing slack-variables 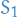 and
and  .
.
- cannot be a basic variable (included in the basis) for
 , even though it appears only in this constraint, since it would imply a negative value for it (i.e.
, even though it appears only in this constraint, since it would imply a negative value for it (i.e. 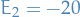 ), and the resulting basic solution would not be feasible
), and the resulting basic solution would not be feasible  does not even include an auxillary variable
does not even include an auxillary variable
To fix these two problematic constraints and we "synthesize" an initial BFS by introducing additional artifical variables 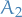 and
and  for and , with
for and , with 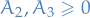 .
.
- Initial BFS is
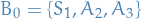 with
with 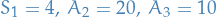
- This alters the structure, and therefore the content, of the original LP
- Easy to check that this BFS
 (together with the implied zero values of the nonbasic variables) is not feasible for the original LP!
(together with the implied zero values of the nonbasic variables) is not feasible for the original LP! - BUT, if we obtain another BFS for the modified problem in which the artifical variables are non-basic , then this BFS would also be feasible for the original LP (since the artifical variables, being nonbasic, would be zero in the "canonical form")
To get artifical variables  to zero, we try to achieve the following objective:
to zero, we try to achieve the following objective:
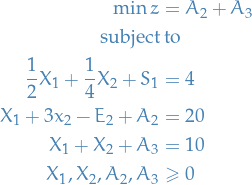
This is known as Phase 1 of the Simplex method. Observe
- If original LP has a feasible solution, then nonnegativity of and implies optimal value for altered LP will be zero!
- Hence, at the end of this altered LP we will have a feasible solution for the original formulation!
- If, due to the strictly positive optimal objective value for altered LP, artifical variables are absolutely necessary to obtain a feasible solution for this set of constraints => original LP is infeasible
Therefore, all we do is solve the altered system, and if we get a solution for this without the introduced artifical variables in the BFS, we have an initial BFS for the original LP!
TODO Simplex method
Have an LP in (primal) form:
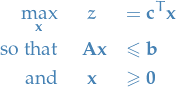
Note the inequality of constraints.
Add slack variables
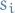 to each inequality, to get:
to each inequality, to get:
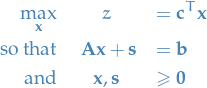
Why bother?
- We're now left with the familiar (primal) form of a LP
To make it completely obvious, one can let
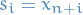 and add the identity matrix to the lower-left of the matrix
and add the identity matrix to the lower-left of the matrix 

Then we can write the problem with slack-variables as a system of linear equations:
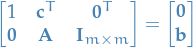
- Every equality constraint now has at least one variable on the LHS with coeff. 1, which is indep. of the other inequalities
Picking one such variable for each equality, we obtain a set
 of variables called a basis (variables in the basis are called basic variables); an obvious choice is
of variables called a basis (variables in the basis are called basic variables); an obvious choice is

- We're now left with the familiar (primal) form of a LP
Rearrange constraints to get
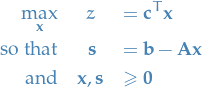
Just for the sake of demonstration, suppose all constraints are positive, i.e.
 . Then clearly the best solution is just letting
. Then clearly the best solution is just letting 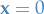 . This then corresponds to a vertex.
. This then corresponds to a vertex.
Nowe we have some initial suggestion for a solution, i.e. a basic feasible solution (BFS) with basis
.
To find other possible solutions; pivot!
Let the current basis be
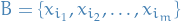
with
 being a variable on the LHS of the r-th constraint
being a variable on the LHS of the r-th constraint  (in the above rearrangement).
We then suggest a new basis
(in the above rearrangement).
We then suggest a new basis 

i.e. removing
and choosing some other  on the LHS of constraint , which is performed as follows:
on the LHS of constraint , which is performed as follows:
- Assuming involves , rewrite using
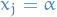
- Substitute in all other constraints
 , obtaining constraints
, obtaining constraints 
New constraints
have a new basis
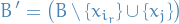
- Substitute in the objective
 so that again only depends on variables not in basis
so that again only depends on variables not in basis
- Assuming
Of course, we're not going to pivot no matter what! We pivot if and only if:
- New constants , since this is a boundary condition
- New basis must at least not decrease objective function
Consider a new candidate basis:

for some 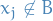 , i.e.
, i.e.
- Replace by where is non-basic variable currently used in constraint
- Rewrite cosntraint such that we get an expression for
Selecting an entering variable (to the basis)
- Given that at every objective-improving iteration the Simplex algorithm considers adjacent bfs's, it follows that only one candidate non-basic variable enters the basis
- Want variable with greatest improvement to the objective to enter basis
- For a variable to enter, we need one to leave:
Simplex Tableau
Take a LP-problem in primal form, we can write it as an augmented matrix with the following:
- 1st column corresponds to coefficent of (objective function)
- 2nd through n + 1 corresponds to coefficients of , i.e.

- Last (n + 2) column is the constant in the objective function and RHS of constraints
Then we can write
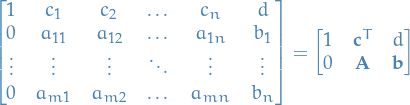
where  is simple the value takes on if all variables are zero, i.e.
is simple the value takes on if all variables are zero, i.e.

usually we set this to zero, 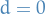 .
.
Now, this is just a linear system, for which there exists
- if
 : independent variables
: independent variables
- when we've solved for the constraints, the rest of the variables are simply functions of the constraints
- when we've solved for the
- if
 : independent variables (might not be able to satisfy the constraints)
: independent variables (might not be able to satisfy the constraints)
Now we simply make use of Gaussian Elimination to solve this system;
- unless the matrix has linearly indep. columns and is
 , we do not have a unique solution!
, we do not have a unique solution! - therefore we simply look for solutions where we have some linearly independent columns, which we say form our basis (see BFS)
But what if the are not all non-negative?!
They can't be yah dofus! You have optimality exactly when they are all non-negative.
If they're not, you pivot!
Duality
Notation
Linear problem (primary form)
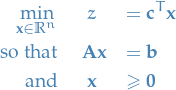
- is the variables to minimize over
Linear problem (dual form)
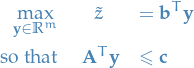
Primal form
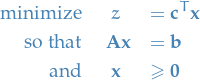
Dual form
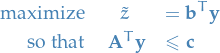
Weak Duality Theorem

That is,

Farkas Lemma
Let  and
and  .
.
Then exactly one of the following statements is true:
- There exists an
 such that
such that  and
and 
- There exists a
 such that
such that 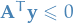 and
and 
The way I understand Farkas lemma is as follows:
 , then clearly
, then clearly  such that
such that - , then we can find some vector such that the hyperplane defined by

i.e.
 is the norm of
is the norm of  , such that
, such that

or, equivalently,

Where:
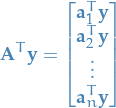
From now on, we'll use the notation
 .
Now, what if we decided to normalize each of these
.
Now, what if we decided to normalize each of these  ? Well, then we're looking at the the projection of onto the
? Well, then we're looking at the the projection of onto the  .
Why is this interesting? Because the inequality
.
Why is this interesting? Because the inequality

is therefore saying the the projection of
onto , is non-positive in all entries, i.e. the angle between and all vectors in / is  !!! (including the full
In turn, this implies that the hyperplane , which is defined by all vectors perpedincular to , i.e. angle of
!!! (including the full
In turn, this implies that the hyperplane , which is defined by all vectors perpedincular to , i.e. angle of  , lies "above" , since
, lies "above" , since  .
Finally, we're computing
.
Finally, we're computing  , which is obtaining the angle between the and . Then saying that
, which is obtaining the angle between the and . Then saying that

is equiv. of saying that the angle between
and is  .
BUT, if is an angle of wrt. , AND is an angle with . Then, since the hyperplane is at wrt. , then lies somewhere between and the hyperplane , which in turn lies above , hence lies between and .
.
BUT, if is an angle of wrt. , AND is an angle with . Then, since the hyperplane is at wrt. , then lies somewhere between and the hyperplane , which in turn lies above , hence lies between and .
Strong Duality
The optimal (maximal) value for the dual form of a LP problem is also the optimal (minimal) value for the primal form of the LP problem.
Let the minimal solution to the primal problem be

Then define
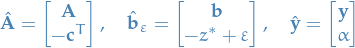
with 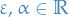 . We then have two cases for
. We then have two cases for  :
:
 , in which case we 1. of Farkas lemma because
, in which case we 1. of Farkas lemma because 

 , in which case there exists no non-negative solution (because
, in which case there exists no non-negative solution (because  is already minimal) and we have Farkas lemma case 2. Thus, there exist and
is already minimal) and we have Farkas lemma case 2. Thus, there exist and  , such that
, such that

or, equivalently,

Now, we can find
 such that
such that

Then, letting
, from the equation above, we would get

Which we observe is only possible if
 , since
, since  .
is simply the normal vector of the hyperplane, thus we can scale it arbitarily; let's set
.
is simply the normal vector of the hyperplane, thus we can scale it arbitarily; let's set 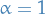 :
:
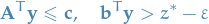
Observe that
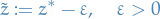
is a feasible value for the objective of our dual problem. From the Weak Duality Theorem, we know that

But, we've just shown that we can get arbitrarily close to
, hence at optimality (maximal) value of our dual form we also have !!!
Sources
Footnotes:
Unbounded LPs allows infinitively large values for our objective function, i.e. not interesting.