RNN: Recurrent Neural Network
Table of Contents
Notation
 - time
- time - feature-vector at step
- feature-vector at step  - hidden state at time
- hidden state at time
Recurrent Neural Networks (RNN)
Notation
 - weight matrix for hidden-to-hidden
- weight matrix for hidden-to-hidden - weight matrix for input-to-hidden
- weight matrix for input-to-hidden - weight matrix for hidden-to-output
- weight matrix for hidden-to-output
Forward
The major points are:
- Create a time-dependency by encoding the input and some previous state into the new state
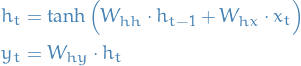 1
1
We can of course add any activation function at the end here, e.g. sigmoid, if one would lie such a thing.
Backward
Whenever you hear backpropagation through time (BPTT), don't give it too much thought. It's simply backprop but summing gradient the contributions for each of the previous steps included.