Maximum entropy models
Table of Contents
Notation
 for a probability distribution denotes the integral over all inputs if continuous, and sum if discrete
for a probability distribution denotes the integral over all inputs if continuous, and sum if discrete
Overview
- MaxEnt models are models which attempts to maximize the information (Shannon) entropy wrt. constraints on statistics (e.g. first moment) of the "data" or underlying generating distribution
The optimization problem is then
![\begin{equation*}
\begin{split}
\max_{p} \quad & H[p] \\
\text{subject to } \quad \int p(\mathbf{x}) \dd{\mathbf{x}} = 1, \qquad & \int f_i(\mathbf{x}) p(\mathbf{x}) \dd{\mathbf{x}} = F_i, \quad i = 1, \dots, n
\end{split}
\end{equation*}](../../assets/latex/maximum_entropy_models_d7dac18cbc43ee1cd7542e9fb3a0e2356816a280.png)
where
 are arbitrary functions on the input-space, and
are arbitrary functions on the input-space, and  are the values which the expectation of should take
are the values which the expectation of should take
Using Lagrange multipliers, we can write this as the minimization problem
![\begin{equation*}
\begin{split}
\mathcal{L}[p] =& - H[p] + \sum_{i}^{} \lambda_i \Bigg( \left\langle f_i \right\rangle_{\text{obs}} - \int f_i(\mathbf{x}) p(\mathbf{x}) \dd{\mathbf{x}} \Bigg) \\
&+ \gamma \Bigg( 1 - \int p(\mathbf{x}) \dd{\mathbf{x}} \Bigg)
\end{split}
\end{equation*}](../../assets/latex/maximum_entropy_models_317558f1a2b6f215df782235e9654a719ba0bd63.png)
where we've chosen these arbitrary
to be the observed expectations of .
Solving for
 by taking the functional derivative and setting to zero:
by taking the functional derivative and setting to zero:
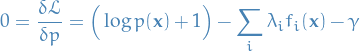
The general form of the maximum entropy distribution is then given by

where

Furthermore, the values of the Lagrange multipliers  are chosen to match the expectations of the functions
are chosen to match the expectations of the functions  , hence
, hence

i.e. the parameters of the distribution can be chosen s.t.
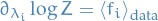
Same holds for discrete random variables.
Still gotta estimate those moments yo!
Principle of Maximum Entropy
Shannon entropy
Say we want to define a function  describing the information, in terms of an event
describing the information, in terms of an event  with probability
with probability  ; that is, how much information is acquired if we observe event ?
; that is, how much information is acquired if we observe event ?
Such a function one would expect to have the following properties:
 is monotonoically decreasing in
is monotonoically decreasing in  , i.e. if is large, then we gain little "information" by observing event .
, i.e. if is large, then we gain little "information" by observing event . , i.e. "information" is a non-negative quantity.
, i.e. "information" is a non-negative quantity. , i.e. events occuring with a probability 1 provides no information.
, i.e. events occuring with a probability 1 provides no information. for two independent events and
for two independent events and  , i.e. the "joint information" of two independent random variables is the information of both added together.
, i.e. the "joint information" of two independent random variables is the information of both added together.
It turns out that the following equation satisfies exactly these properties (see here for how to deduce it):
The average amount of information received for an event is given by

Justification
- Consider discrete probability distribution among
 mutually exclusive propositions
mutually exclusive propositions - Most informative distribution would occur when exactly one of the propositions was known to be true, in which case the information entropy would be zero (no "uncertainty").
- Least informative distribution would occur when all propositions are equally likely (uniform), in which case the information entropy would be equal to its maximum possible value:
 .
. - One can therefore view information entropy as a numerical measure of how uninformative a particular distribution is, ranging from zero to one.
- Choosing a distribution with maximum entropy we are in a way choosing the most uninformative distribution possible, and to choose a distribution with lower entropy would be to assume information which is unknown.
Walllis derivation - combinatorial argument
- https://en.wikipedia.org/wiki/Principle_of_maximum_entropy?oldformat=true#The_Wallis_derivation
- Makes no reference to entropy as a measure of "uncertainty"
- Want to make probability assignment to mutually exclusive propositions
- Let
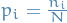 be the probability of each of the propositions, with
be the probability of each of the propositions, with  being the number of times the i-th proposition "occurs"
being the number of times the i-th proposition "occurs" Probability of any particular results is the multinomial distribution:

Most probably results it the one which maximizes
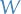 , equivalently, we can maximize any monotonic increasing function of :
, equivalently, we can maximize any monotonic increasing function of :
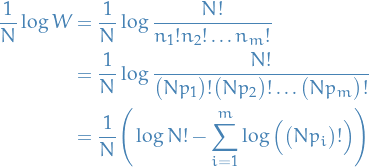
Assuming
 we have
we have
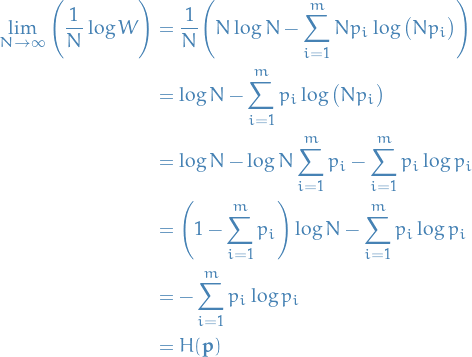
Issues
- Information about the probability distributions is intended to exist a priori
- Information provided by measurements is only an estimate of "true" information, hence we require methods for entropy estimation.
Bibliography
Bibliography
- [paninski_2003] Paninski, Estimation of Entropy and Mutual Information, Neural Computation, 15(6), 1191–1253 (2003). link. doi.