Exercises
Table of Contents
Information Theory, Inference and Learning Algorithms
6.14
Since there is no covariance between the different dimensions, i.e. the 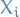 are independent of all
are independent of all  with
with  , we know that
, we know that
![\begin{equation*}
\mathbb{E}[r^2] = \mathbb{E} \bigg[ \sum_{i=1}^{N} x_i^2 \bigg] = \sum_{i=1}^{N} \mathbb{E}[x_i^2]
\end{equation*}](../../assets/latex/exercises_02f1f6f84e58166078904da4623c7528573be04a.png)
where each of the  are following
are following  , hence
, hence
![\begin{equation*}
\mathbb{E} \big[ x_i^2 \big] = \text{Var}(x_i) - \big( \mathbb{E}[x_i] \big)^2 = \sigma^2 - 0 = \sigma^2
\end{equation*}](../../assets/latex/exercises_9b3443eac5a74b5b3d52408d907d6e736f6c1384.png)
Hence,
![\begin{equation*}
\mathbb{E} \big[ r^2 \big] = \sum_{i=1}^{N} \sigma^2 = N \sigma^2
\end{equation*}](../../assets/latex/exercises_641b5cf66f1d38a8109acbb77cd837421638bd1d.png)
The variance is then given by
![\begin{equation*}
\text{Var}(r^2) = \mathbb{E} \big[ r^4 \big] - \Big( \mathbb{E} \big[ r^2 \big] \Big)^2
\end{equation*}](../../assets/latex/exercises_e6bf31b29bb0ec52bc00f36447f4817d69cd7857.png)
where
![\begin{equation*}
\mathbb{E} \big[ r^4 \big] = \mathbb{E} \Bigg[ \bigg( \sum_{i=1}^{N} x_i^2 \bigg)^2 \Bigg] = \sum_{i=1}^{N} \mathbb{E}\big[ x_i^4 \big] + \sum_{i \ne j}^{} \mathbb{E}\big[x_i^2 x_j^2 \big]
\end{equation*}](../../assets/latex/exercises_a53efd9e46542106f45294d113425342b58a5dd4.png)
But since there is no covariance between the different , the second sum vanishes, and since
![\begin{equation*}
\mathbb{E} \big[ x_i^4 \big] = \int_{- \infty}^{\infty} x_i^4 \frac{1}{\sqrt{2 \pi} \sigma} \exp \bigg( \frac{x_i^2}{2 \sigma^2} \bigg) \ dx_i
= 3 \sigma^4
\end{equation*}](../../assets/latex/exercises_c54826fb3a6bf212f075bc9d47d27becb679ac2a.png)
(which we knew from the hint 6.14 in the book). Hence
![\begin{equation*}
\text{Var}(r^2) = \sum_{i=1}^{N} \mathbb{E} \Big[ x_i^4 \Big] - \big( \mathbb{E}[x_i^2] \big)^2 = \sum_{i=1}^{N} 3 \sigma^4 - \sigma^4 = 2 N \sigma^4
\end{equation*}](../../assets/latex/exercises_85ce648566c7b5522bbb97c302d1646596f97f76.png)
This all means that for large  , we will have
, we will have

And since 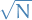 will be neglible for large , compared to (of course assuming
will be neglible for large , compared to (of course assuming  is finite), then
is finite), then

as watned. The "thickness" will simply be the  , i.e. twice the variance of
, i.e. twice the variance of  .
.
Either by:
- Computing an dimensional integral :)
- Empirically looking at
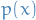 for some
for some  and making use of the symmetry of the Gaussian to infer that all
and making use of the symmetry of the Gaussian to infer that all  with same radius have the same probability, and that
with same radius have the same probability, and that  decreases when moves away (in whatever "direction" / dimension) from the mean
decreases when moves away (in whatever "direction" / dimension) from the mean
We can observe that the majority of the probability mass is clustered about this "shell".
Bibliography
Bibliography
- [mackay2003information] MacKay, Kay & Cambridge University Press, Information Theory, Inference and Learning Algorithms, Cambridge University Press (2003).